Technical note
The aim of this article is to introduce the architecture of Flux, a state-of-the-art model for text-to-image generation. We first review Diffusion and Flow Matching frameworks, then discuss the architectural shift from U-Nets to Diffusion Transformers.
Text-to-image generation is a rapidly evolving field. In recent years, researchers and engineers have focused much of their effort on diffusion models and flow models.
The most general modern way to think about generative modeling is through the Flow Matching framework. At its core, this framework learns a continuous process that transforms a simple prior distribution into a complex target data distribution.
This transformation is defined by a time-dependent probability path, , which smoothly morphs into as time goes from to . The evolution of a point along this path is governed by a learned vector field :
The goal is to learn such that solving this ODE from noise back to data produces valid samples.
Diffusion Models
Diffusion models realize this objective through a predefined Gaussian noising process. A fixed forward process gradually injects noise into data; a learned reverse process predicts how to remove that noise.
In practice, diffusion models learn to denoise. From that denoising function, one can derive the score or vector field needed to move from noise back to data.
Flow Models
More recent flow models, especially rectified flow, provide a more direct solution. The key idea is to construct paths between and that are close to straight lines:
This makes the vector field easier to learn and can support high-quality sampling with fewer steps.
| Model family | Strengths | Tradeoffs |
|---|---|---|
| Diffusion models | Stable training, diverse generation | Slow sampling with many steps |
| Rectified flows | Faster sampling, direct vector-field learning | Newer and still rapidly evolving |
U-Net vs Diffusion Transformers
In a diffusion model, the denoiser is the core learnable component. Historically, this component has often been a U-Net.
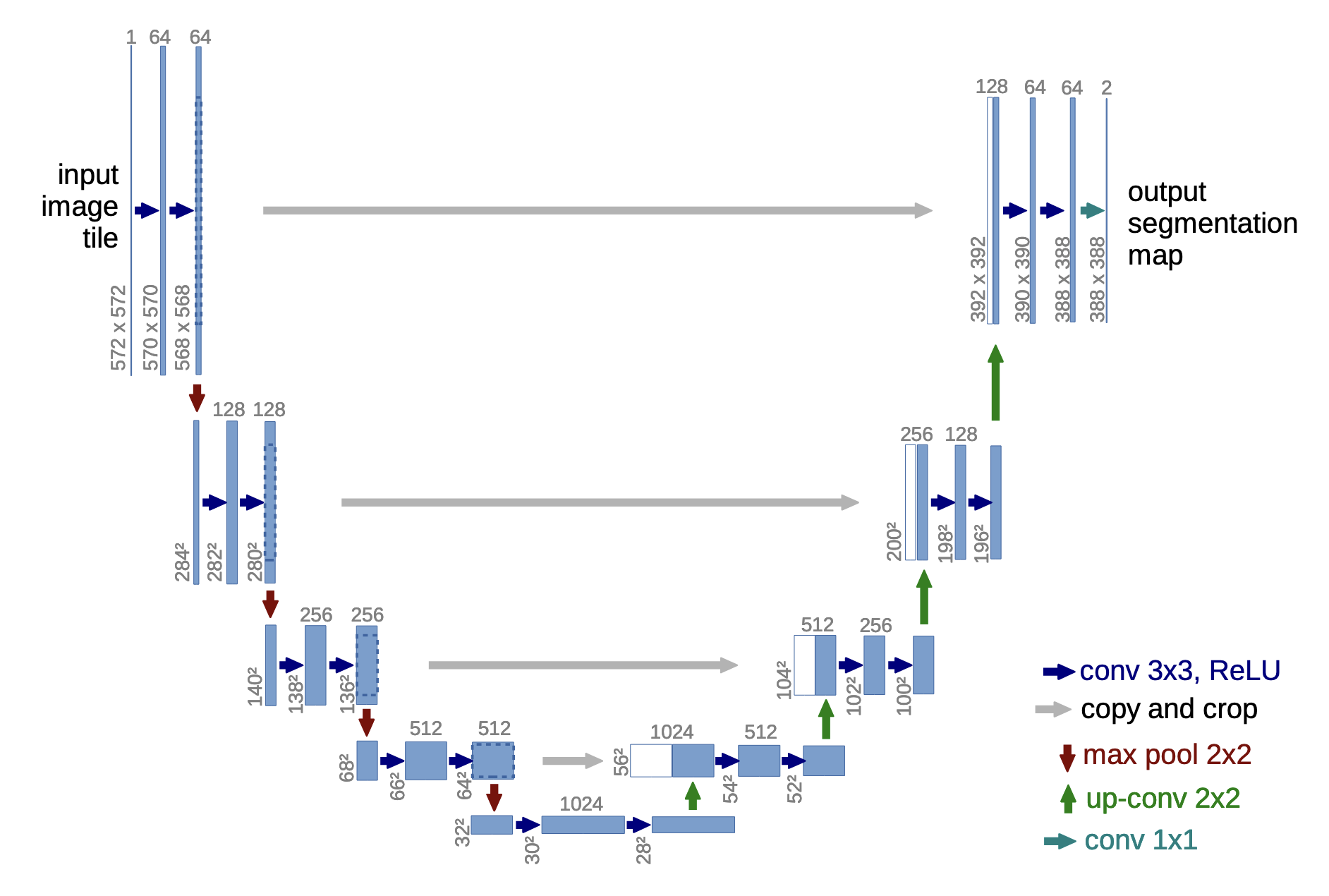
U-Nets combine downsampling, upsampling, and skip connections. They are powerful, but architecturally complex.
Diffusion Transformers instead treat denoising as a sequence modeling task: image patches become tokens, and the denoiser becomes a Transformer over image and conditioning sequences.
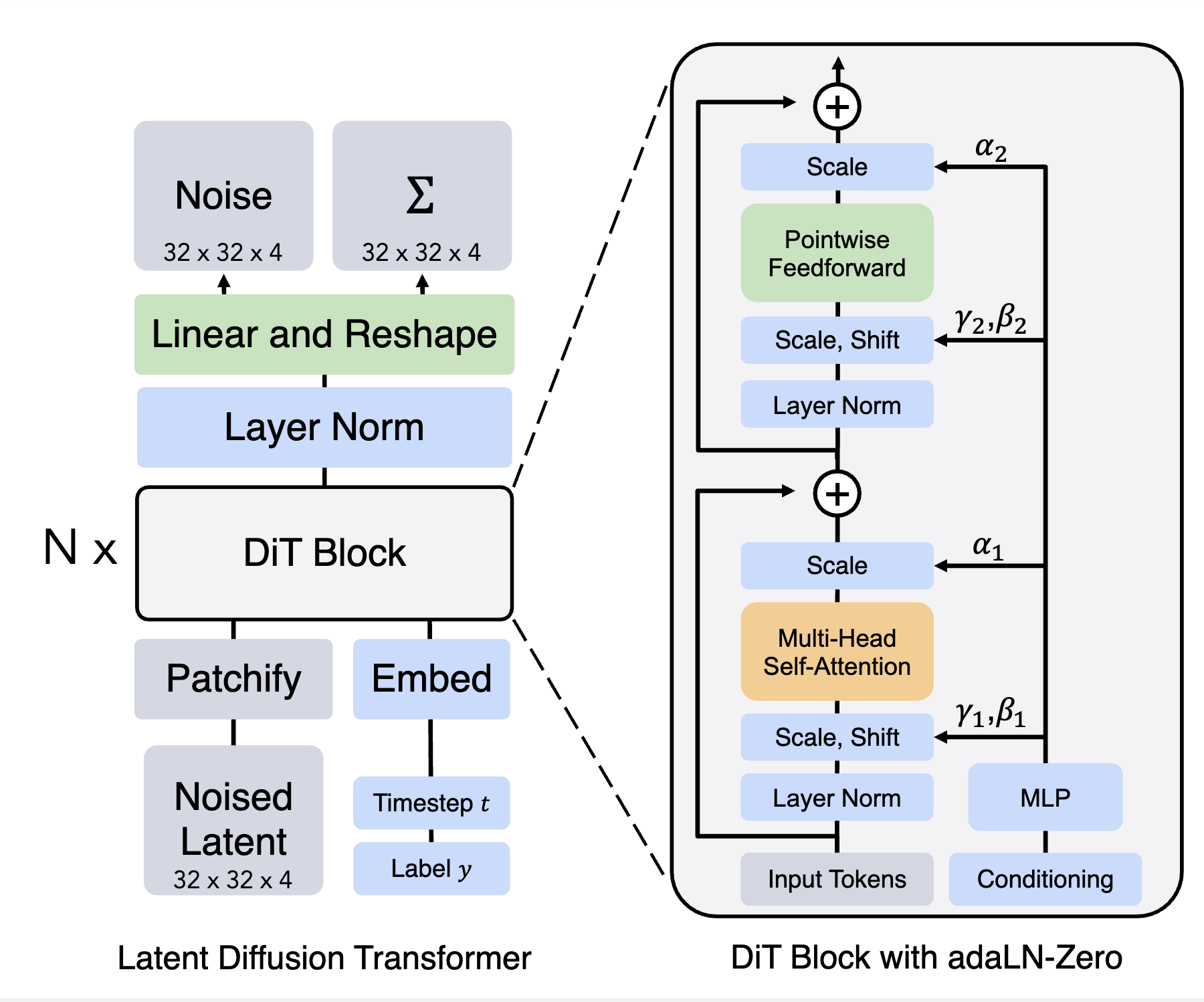
Flux
Flux combines flow matching with a transformer-based denoiser. Its architecture can be read as a dual-transformer system that integrates text, image, and timestep information.

The model prepares text conditioning, time conditioning, and latent image patches before passing them through a multi-stage transformer backbone. The result is an elegant architecture that avoids much of the complexity of older U-Net-based systems while keeping strong generation quality.
Takeaway
The broader trend is clear: text-to-image systems are moving toward cleaner Transformer-based denoisers and more direct flow-based sampling objectives. Flux is a strong example of that shift.