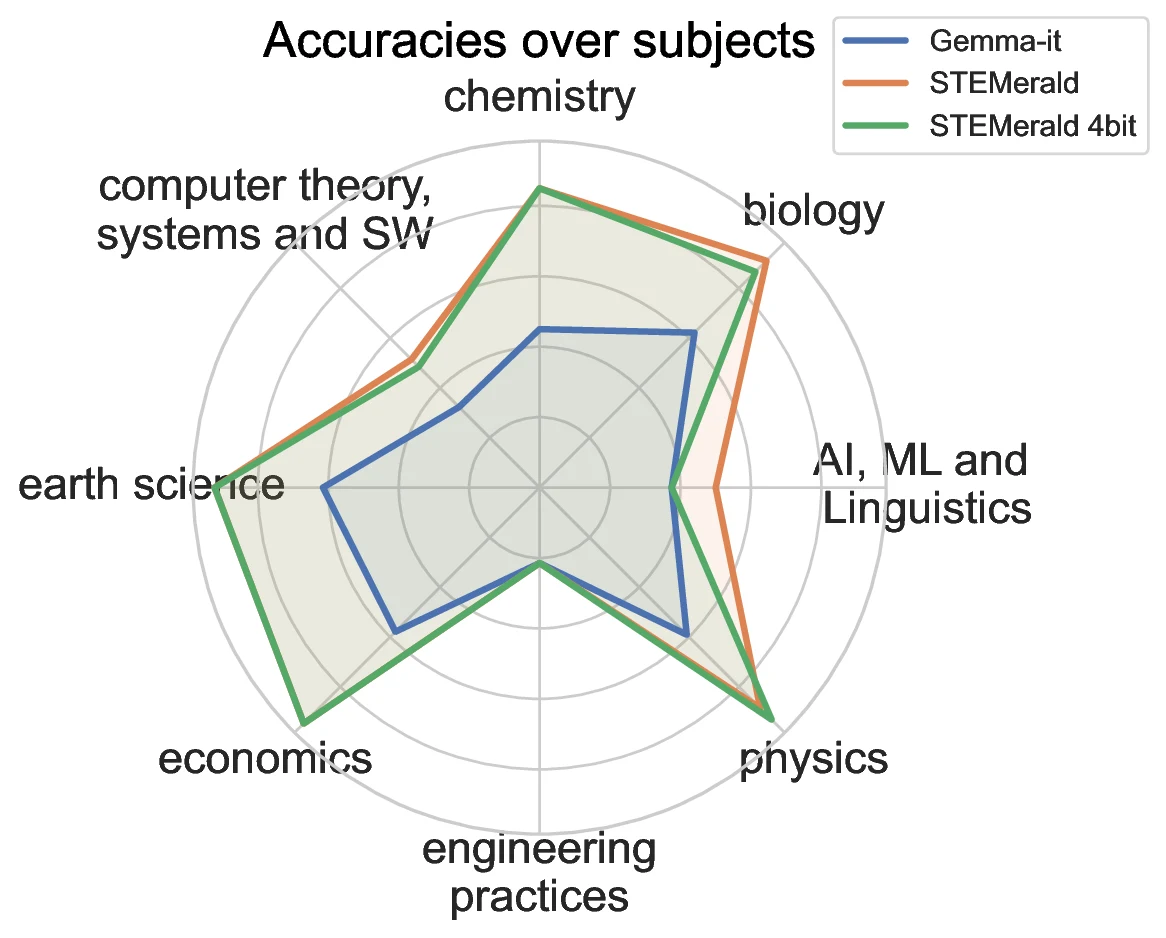
STEMerald: A Gemma-Based Course Assistant
Reached 75% accuracy on university-level STEM multiple-choice QA and compressed the model to a 2GB 4-bit variant.
Archive
Reached 75% accuracy on university-level STEM multiple-choice QA and compressed the model to a 2GB 4-bit variant.
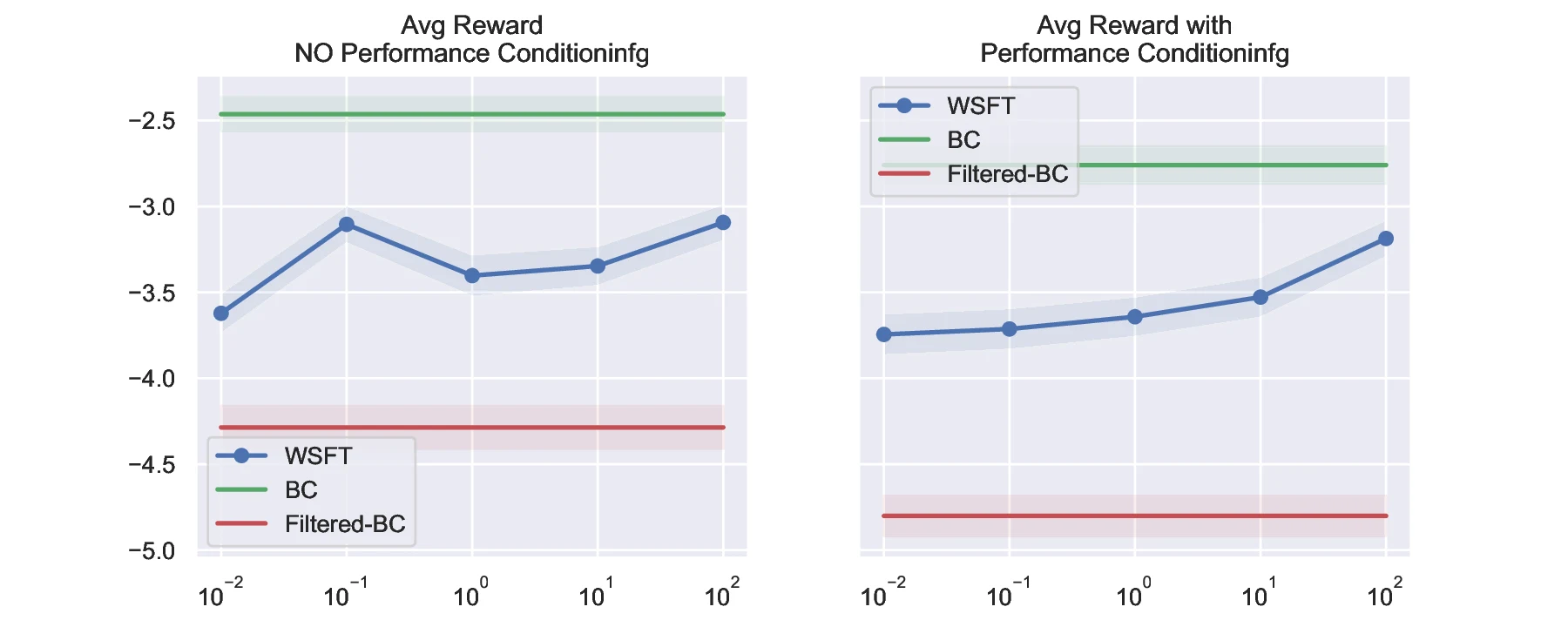
Studied Reward-Weighted Behavioral Cloning as a practical bridge between Behavioral Cloning and Filtered-BC.
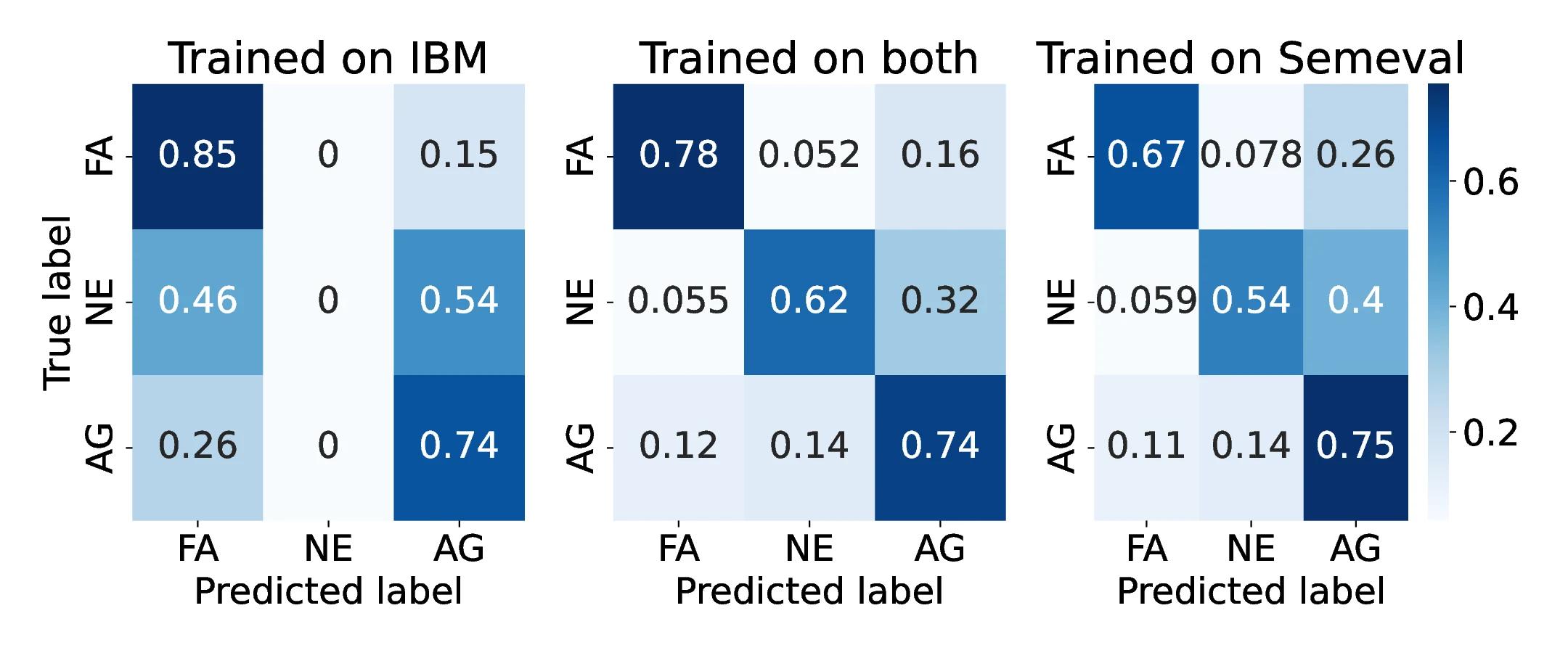
Mistral-7B achieved strong cross-dataset results, including 0.76 F1 on SemEval and 0.92 F1 on IBM-Debater in the combined setting.